Reading Tweets Using Python
In this post we’ll see how to use Python to get the tweets we plotted in Rude Britannia and Exploring Rude Britannia. This is a code-centric post so you have been warned! This is not a best practises post, but simply my implementation.
I’ve written this post as if I’m talking you through the code. If you don’t have the patience you can get the full code here.
Load Packages
Tweepy does much of the heavy lifting
import tweepy as tpwe’ll need to import a custom module for our twitter authentication codes
import importlib.utilthe results are a JSON set which I store in a MongoDB
import json
from pymongo import MongoClientthis pair are always useful…
import pandas as pd
import numpy as npwe’ll need to read a csv to build a search string
import csvand let’s finally bring in this for timing how long stuff takes.
import timeAuthenticate with Twitter
To read tweets our script will need to sign into Twitter. To do this, create a Twitter account, go to https://apps.twitter.com/ and make some keys and access tokens. The access tokens don’t expire so you only need to do this once.
I think of the consumer keys as an entrance fee to a nightclub and the access tokens are the rubber stamp that tells the bouncer you’ve paid. Just like a club, one generous person can pay the entry for many people and if you cause any trouble the Twitter bouncers will kick you (and possibly your mates) out!
To get the location of tweets you must enable location broadcasting on your Twitter account, so you might want to turn this on now.
Stick the keys into the code below and you should be good to go. I keep this entire snippet out of my git repo but you may only want to exclude the keys.
def twitter_auths():
import tweepy
auth = tweepy.OAuthHandler(<consumer key>, <consumer secret>)
auth.set_access_token(<access token>, <access token secret>)
return authFor more information see the Tweepy documentation.
Create Connections
We first load the authentication we created in the previous snippet
spec = importlib.util.spec_from_file_location("twitter_auths",
"<file path>Not_Controlled/twitter_auths.py")
conn = importlib.util.module_from_spec(spec)
spec.loader.exec_module(conn)and use it to open a connection to the Twitter API.
auth = conn.twitter_auths()
api = tp.API(auth)We then connect to a local Mongo database called “twitter” that has a collection called “twitter_collection”.
client = MongoClient('localhost', 27017)
db = client['twitter']
collection = db['twitter_collection']Find the UK
The Twitter API has places, each place has a unique ID. Places can be anything from countries, regions, cities, pubs and so on. I only care about tweets that come from the UK, so I find all places that could be ‘United Kingdom’, eyeball the result set and get the ID. Once you have the ID you don’t need to query the places.
places = api.geo_search(query="United Kingdom", granularity="country")If you want a different country change the ID accordingly.
UK = api.geo_id('6416b8512febefc9')This stackoverflow helped me greatly.
Build a Search String
I load in this set of rude words but you can have whatever you want - it doesn’t even have to be rude.
with open('<file path>\\swearwords.csv') as csvfile:
rude_words = csv.reader(csvfile)
for row in rude_words:
rude_words = rowWe can now use the loaded words to build our search string. Be careful, searching for too many terms (more than 20 or so) will throw an error which this code doesn’t handle.
search_string = '%20OR%20'.join(rude_words)
search_place_string = search_string + '%20place:' + UK.id Seed the Query
People are always making lots of new tweets so we will be querying a constantly changing list. To create a reference point we grab any tweet, there’s nothing special about it, the tweet doesn’t even have to be one we care about, it’s simply so we don’t keep querying the same tweets as the list changes.
first_tweet = api.search(q = search_place_string, count = 1)The Twitter API expects a collection of tweets, even though we’ve only returned one tweet we have to treat the result as a set. We ‘loop through’ the set, convert it to JSON and get the ID of our seed tweet. This will be the biggest ID we query up to.
for t in first_tweet:
data = json.dumps(t._json)
data = json.loads(data)
max_id = data['id']If you don’t leave enough time between executions, this seed method can return duplicate tweets. I just make sure to wait long enough before successive runs, I also have some code that sorts duplicates in my database. I’ll leave the proper solution as an exercise for the reader 😉
Query the API
We’re going to query the API about 20 times, each time getting 100 tweets - giving us around 2000 tweets. Should we desire, we can query the API up to the rate limit, getting 100 tweets with each query.
start_time = time.time()
requests = 20
tweets_added = 0This performs the query against the API. A line further down the page decreases the number of requests left to perform.
while requests > 0:
tweets = api.search(q = search_place_string, count = 100, max_id = max_id) Add Custom Meta-Data
We now convert the returned data to JSON and add the search string and a comment to the returned set. These prove invaluable for analysing the data because it lets us know if a type of tweet was returned through luck or if we actively searched for it.
for tweet in tweets:
data = json.dumps(tweet._json)
data = json.loads(data)
data['search_string'] = search_place_string
data['search_comment'] = 'rude_tweet' Convert Location Boxes to Discrete Points
When users tweet, we’re told that it came from somewhere inside a geographic box but we don’t know precisely where. The boxes give us an idea where the tweet came from without telling us the exact co-ordinates so we can’t for example, figure out the street someone lives on.
if data.get('place'):
box_coords = data['place']['bounding_box']['coordinates'][0]
box_lwr_left = box_coords[0]
box_lwr_right = box_coords[1]
box_upr_right = box_coords[2]
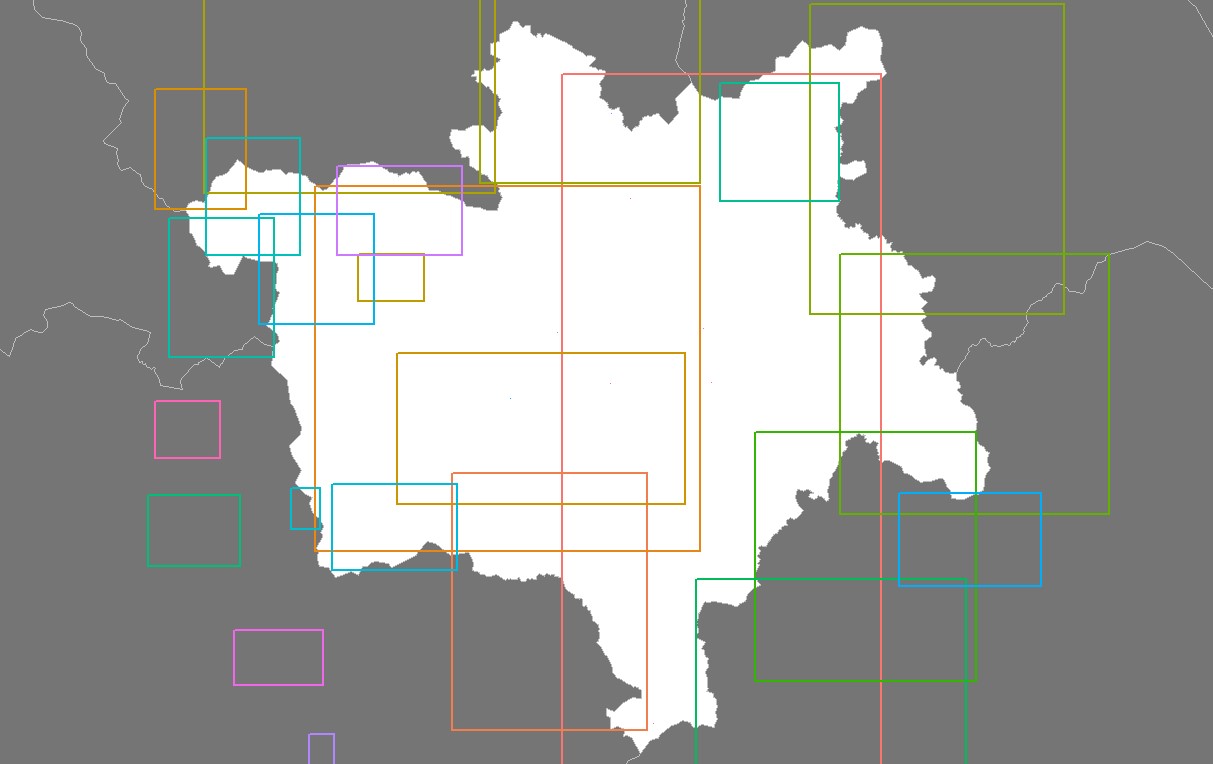
box_upr_left = box_coords[3]I’ve created a plot in R demonstrating how some of these boxes look around Manchester. It uses code similar to Rude Britannia. We can see that boxes are unequal in size and often overlap or nested. If you look closely you’ll see some points that look like dust on your screen, these are actually really small boxes.
We take the center of the boxe and record it against the tweet.
lat_center = ((box_upr_left[1] - box_lwr_left[1]) / 2) + box_lwr_left[1]
lon_center = ((box_lwr_right[0] - box_lwr_left[0]) / 2) + box_lwr_left[0]
data['place_center_lat'] = lat_center
data['place_center_lon'] = lon_centerInsert into DB
We now insert the tweet into our database. This code attemps the replace an existing tweet (based on it’s Twitter ID), if the tweet doesn’t exist in our database we add it (upsert = True).
if not data.get('retweeted_status'):
tweets_added += 1
collection.replace_one({'id' : data['id']}, data, upsert = True)The documentation for collection.replace is here.
Seed the Next Query
As we process each tweet, we check if it’s ID is less then the reference point we seeded our query with. If it is, we move the reference point backwards so that our next query doesn’t return tweets we already have.
if max_id > data['id']:
max_id = data['id'] - 1
requests -= 1
exec_time = time.time() - start_time Thanks for reading. If you followed everything correctly you should now have a database of tweets that you can use to follow Rude Britannia.